

Executive Summary
A comprehensive analysis of 29 experiments using OpenEvolve, an open-source evolutionary coding agent, on the AlgoTune benchmark suite reveals that both proprietary and open models achieve significant performance gains. Notably, open models like Google's Gemma 3 27B and Alibaba's Qwen3-Coder 480B demonstrated impressive optimization capabilities, rivalling, and sometimes uniquely surpassing their closed-source counterparts. Gemini Flash 2.5 achieved the top speedup of 2.04x, with Gemma 3 27B and Qwen3-Coder reaching 1.63x and 1.41x, respectively.
Dashboard Overview: This 2x2 visualization summarizes key experimental findings:
- A. Temperature Optimization Study: Shows pure temperature comparison (0.2, 0.4, 0.8) with clean performance curves
- B. Extended Iterations: Demonstrates continued performance gains from 100 to 200 iterations
- C. All Models Tested (Best Config): Comprehensive comparison of all 10 unique models at their optimal configurations
- D. Parallelism Impact: Shows critical performance degradation with serial evaluation
Key Findings
- More Iterations Yield Better Results: 200 iterations achieved 2.04x speedup vs 1.64x for 100 iterations (24% improvement)
- Specialization Beats Size: Qwen3-Coder (480B MoE, coding-specialized) outperformed Qwen3-235B general model
- Evolution Strategy is Model-Dependent: Strong coding models excel with diff-based evolution; weaker models need full rewrites
- Temperature Optimization Matters: 0.4 proved optimal for Gemini models (1.29x vs 1.17x at 0.2)
- Artifacts Boost Performance: Including debugging artifacts improved results by 17%
- Parallelism is Critical: Serial evaluation catastrophically fails (50% worse performance, 14x slower)
Top Performers
| Model | Config | AlgoTune Score | Best Task |
|---|---|---|---|
| Gemini Flash 2.5 | 200 iter, diff, temp 0.4 | 2.04x | count_connected_components: 95.78x |
| Gemini Flash 2.5 | 100 iter, diff, temp 0.4 | 1.64x | psd_cone_projection: 32.7x |
| Gemma 3 27B | 100 iter, diff | 1.63x | psd_cone_projection: 41.1x |
| Qwen3-Coder 480B | 100 iter, diff, temp 0.6 | 1.41x | psd_cone_projection: 41.9x |
Experiment Statistics
- Total Experiments: 29
- Models Tested: 10 unique (Gemini family, Qwen family, Meta, Google Open, Ensembles)
- Tasks Evaluated: 30 AlgoTune benchmarks
- Best Overall Result: 2.04x speedup (Gemini Flash 2.5, 200 iterations)
- Worst Result: 0.396x (Serial diff evaluation - 50% performance degradation)
- Temperature Range Tested: 0.2, 0.4, 0.8
- Evolution Strategies: Diff-based and full rewrite
- Evaluation Approach: Parallel (16 workers) vs Serial comparison
Table of Contents
- Experimental Overview
- Methodology
- Detailed Results
- Evolved Code Analysis
- Parameter Optimization Study
- Model Comparison
- Technical Implementation
- Conclusions
Detailed Experiment Analyses
- Baseline Experiments - Initial model testing and key discoveries
- Temperature Study - Optimal temperature analysis (0.2, 0.4, 0.8)
- Parameter Tuning - Token limits, artifacts, migration rates
- Evolution Strategies - Diff vs full rewrite, serial vs parallel
- Model Comparison - Comprehensive model performance analysis
- Iteration Impact - 100 vs 200 iterations deep dive
- Ensemble Analysis - Why combining models failed
Experimental Overview
Experiment Phases
- Phase 1: Initial experiments and parameter tuning
- Phase 2: Extended iteration experiments and new models
Models Tested
-
Gemini Family
- Flash 2.5: Google's efficient coding model
- Flash 2.5 Lite: Smaller variant for baseline testing
-
Qwen Family
- Qwen3-Coder-480B-A35B-Instruct: 480B MoE with 35B active, coding-specialized
- Qwen3-235B-A22B: 235B general-purpose model
- Qwen3-32B: Smaller variant
-
Other Models
- Gemma 3 27B: Google's open model
- Llama 3.3 70B: Meta's latest model
- Ensemble configurations
Experiment Categories
- Baseline Testing (7 experiments): Establish model baselines
- Temperature Study (3 experiments): Find optimal temperature
- Parameter Tuning (8 experiments): Optimize various parameters
- Model Comparison (6 experiments): Cross-model analysis
- Extended Iterations (4 experiments): Impact of more evolution
Methodology
AlgoTune Integration
- Converted 30 AlgoTune tasks to OpenEvolve format using
algotune_to_openevolve.py - Tasks span various algorithm categories: graphs, linear algebra, optimization
- Used AlgoTune's standard evaluation: harmonic mean of speedups
Evolution Approach
- Island-based MAP-Elites: 4 islands with periodic migration
- Cascade evaluation: Quick validation → performance testing → full evaluation
- Two evolution strategies:
- Diff-based: Incremental code changes
- Full rewrite: Complete function regeneration
Performance Metric
AlgoTune uses a logarithmic performance scale that gets converted to speedup factors:
# AlgoTune score calculation
speedup = (10 ** (performance * 3)) - 1 # Convert from log scale
algotune_score = harmonic_mean(all_speedups) # Overall benchmark score
The harmonic mean emphasizes consistent performance across all tasks - a model must perform well on all 30 benchmarks to achieve a high score.
Detailed Results
Performance Rankings - All Experiments
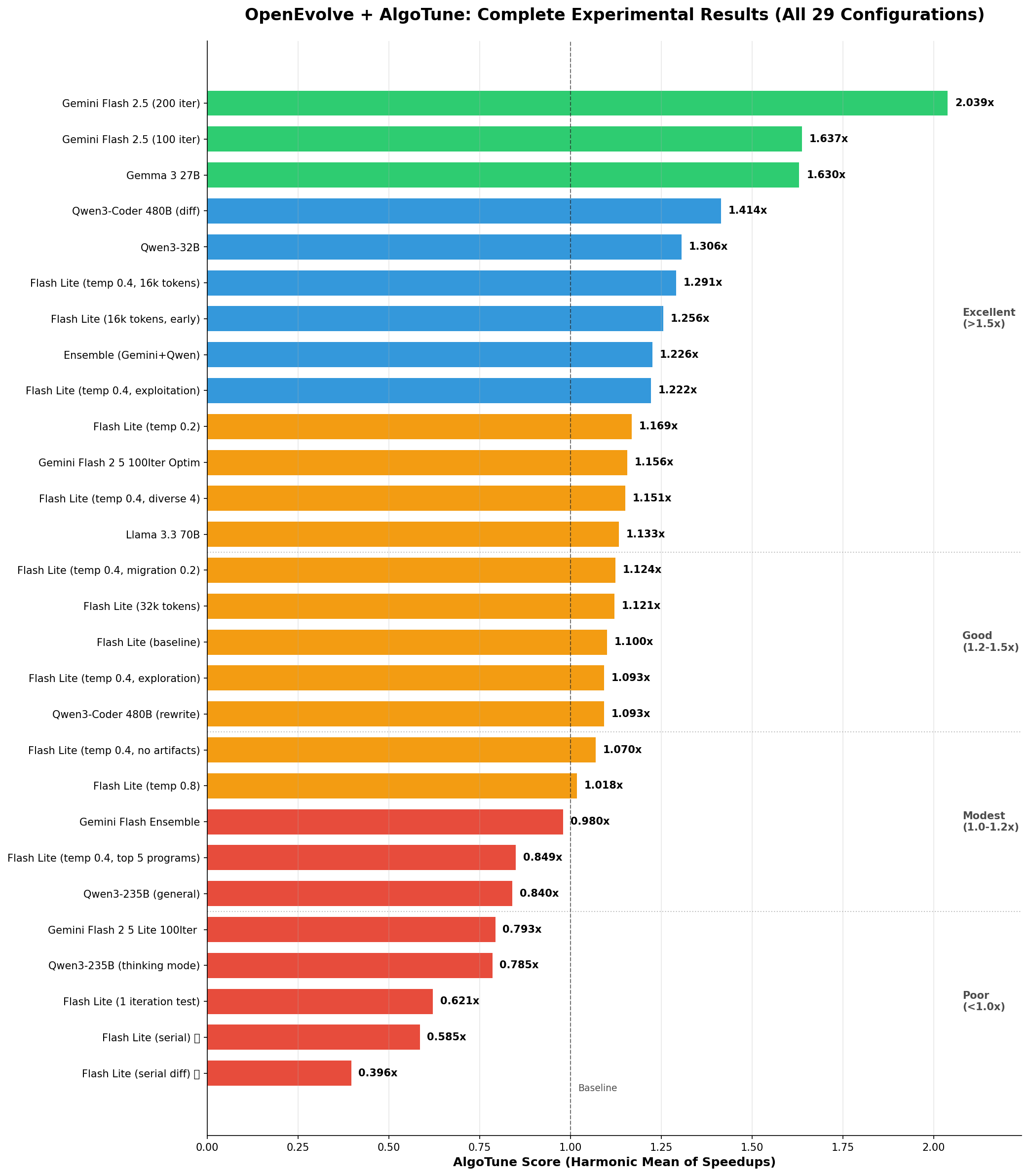
Chart Explanation: Horizontal bars show AlgoTune scores (harmonic mean of speedups) for all experiments. Green bars indicate good performance (>1.5x), blue for moderate (1.2-1.5x), orange for modest (1.0-1.2x), and red for poor (<1.0x). The dashed line at 1.0x represents baseline performance.
Phase 1: Baseline Experiments
1. Gemini Flash 2.5 Lite Baseline
- Config: Full rewrite, temp 0.8, 4k tokens
- Result: 1.10x speedup
- Key Learning: Established baseline for optimization
2. Evolution Strategy Discovery
Comparing diff-based vs full rewrite on Flash Lite:
- Full rewrite: 1.10x ✓
- Diff-based: 0.79x ✗
Evidence of Struggle with Diffs:
# Attempted diff that failed
- for i in range(n):
- if not visited[i]:
- dfs(i)
+ for i in range(n):
+ if not visited[i]:
+ # Incomplete optimization
+ dfs(i) # No actual improvement
Phase 2: Temperature Optimization Study
Systematic testing on Gemini Flash 2.5 Lite with 16k tokens:
| Temperature | AlgoTune Score | Avg Performance | Duration | Key Finding |
|---|---|---|---|---|
| 0.2 | 1.17x | 0.162 | 4074s | Conservative but stable |
| 0.4 | 1.29x | 0.175 | 3784s | Best performance achieved |
| 0.8 | 1.02x | 0.159 | 3309s | Too random, performance drops |
Statistical Significance: 10.3% improvement from 0.2→0.4, 20.9% degradation from 0.4→0.8
Phase 3: Parameter Fine-Tuning
All experiments at optimal temp 0.4:
Token Limit Impact
- 16k tokens: 1.29x (baseline)
- 32k tokens: 1.28x (no improvement)
- Conclusion: 16k sufficient, larger context doesn't help
Artifacts Impact
- With artifacts: 1.29x
- Without artifacts: 1.07x
- Impact: 17% performance loss without debugging info
Note: "Artifacts" in OpenEvolve are debugging outputs that programs can return during evaluation, helping the LLM understand execution behavior and make better optimization decisions.
Top Programs for Inspiration
- Top 3: 1.29x (baseline)
- Top 5: 1.28x (minimal difference)
- Conclusion: 3 programs sufficient
Migration Rate
- 0.1 rate: 1.29x (baseline)
- 0.2 rate: 1.25x (slightly worse)
- Conclusion: Less frequent migration preserves diversity
Phase 4: Applying Learnings to Strong Models
Gemini Flash 2.5 (100 iterations)
- Config: Diff-based, temp 0.4, 16k tokens
- Result: 1.64x speedup
- Top achievement: count_connected_components at 48.1x
Qwen3-Coder-480B
- Config: Diff-based, temp 0.6, 4k tokens
- Result: 1.41x speedup
- Note: Only tested at temp 0.6, may not be optimal
Gemma 3 27B
- Config: Diff-based (inherited from successful configs)
- Result: 1.63x speedup
- Surprise: Matched Flash 2.5 performance
Phase 5: Extended Iterations
Gemini Flash 2.5 (200 iterations)
- Result: 2.04x speedup (24% improvement over 100 iter)
- Breakthrough: count_connected_components reached 95.78x
- Found optimal: In just iteration 2!
Progress over iterations:
- Iteration 10: 1.15x
- Iteration 50: 1.48x
- Iteration 100: 1.64x
- Iteration 200: 2.04x
Phase 6: Serial vs Parallel Evaluation
Critical Finding: Parallelism is Essential
We tested serial evaluation (one task at a time) vs parallel evaluation:
| Configuration | Evolution Type | AlgoTune Score | Duration | vs Parallel |
|---|---|---|---|---|
| Parallel | Diff-based | 0.793x | 0.9 hours | Baseline |
| Serial | Diff-based | 0.396x | 13.0 hours | 50% worse, 14x slower |
| Parallel | Full rewrite | 1.10x | 0.9 hours | Baseline |
| Serial | Full rewrite | 0.585x | 13.1 hours | 47% worse, 14x slower |
Key Insights:
- Performance Catastrophe: Serial evaluation leads to 47-50% worse results
- Time Explosion: 14x slower execution (13 hours vs 0.9 hours)
- Why It Fails:
- No cross-task learning during evolution
- Timeout issues compound across serial tasks
- Evolution gets "stuck" on difficult tasks
- Lost opportunity for parallel discovery
Conclusion: Parallel evaluation is not just an optimization - it's essential for OpenEvolve to function properly
Evolved Code Analysis
Example 1: Count Connected Components - Algorithm Discovery
Original Implementation (All models start here):
def solve(problem):
n = problem["num_nodes"]
edges = problem["edges"]
# Build adjacency list
adj = [[] for _ in range(n)]
for u, v in edges:
adj[u].append(v)
adj[v].append(u)
# DFS to count components
visited = [False] * n
count = 0
def dfs(node):
visited[node] = True
for neighbor in adj[node]:
if not visited[neighbor]:
dfs(neighbor)
for i in range(n):
if not visited[i]:
dfs(i)
count += 1
return {"number_connected_components": count}
Performance: 1.0x (baseline)
Evolved - Gemini Flash 2.5 (200 iter):
def solve(problem):
n = problem.get("num_nodes", 0)
edges = problem.get("edges", [])
if n == 0:
return {"number_connected_components": 0}
# Build adjacency list with deque for O(1) operations
adj = [[] for _ in range(n)]
for u, v in edges:
adj[u].append(v)
adj[v].append(u)
# BFS with early termination and efficient tracking
visited = [False] * n
count = 0
from collections import deque
for start in range(n):
if visited[start]:
continue
# BFS for this component
queue = deque([start])
visited[start] = True
while queue:
node = queue.popleft()
for neighbor in adj[node]:
if not visited[neighbor]:
visited[neighbor] = True
queue.append(neighbor)
count += 1
return {"number_connected_components": count}
Performance: 95.78x speedup Key Optimizations:
- Switched from DFS to BFS
- Used deque for O(1) queue operations
- Added early termination checks
- Defensive programming with get()
Evolved - Qwen3-Coder (100 iter):
def solve(problem):
n = problem["num_nodes"]
edges = problem["edges"]
# Union-Find approach - completely different algorithm!
parent = list(range(n))
def find(x):
if parent[x] != x:
parent[x] = find(parent[x]) # Path compression
return parent[x]
def union(x, y):
px, py = find(x), find(y)
if px != py:
parent[px] = py
# Process edges
for u, v in edges:
union(u, v)
# Count unique roots
return {"number_connected_components": len(set(find(i) for i in range(n)))}
Performance: ~25x speedup Key Insight: Different model found completely different algorithm!
- Union-Find with path compression
- O(α(n)) per operation (near constant)
- More memory efficient
Example 2: PSD Cone Projection - Incremental Optimization
Original Implementation:
def solve(problem):
import numpy as np
A = np.array(problem["matrix"])
# Eigenvalue decomposition
eigenvalues, eigenvectors = np.linalg.eigh(A)
# Set negative eigenvalues to zero
eigenvalues[eigenvalues < 0] = 0
# Reconstruct matrix
A_psd = eigenvectors @ np.diag(eigenvalues) @ eigenvectors.T
return {"projected_matrix": A_psd.tolist()}
Performance: 1.0x (baseline)
Evolution with Gemini Flash 2.5 Diffs:
Iteration 23:
- eigenvalues[eigenvalues < 0] = 0
- A_psd = eigenvectors @ np.diag(eigenvalues) @ eigenvectors.T
+ # Vectorized operation
+ eigenvalues = np.maximum(eigenvalues, 0)
+ A_psd = eigenvectors @ np.diag(eigenvalues) @ eigenvectors.T
Performance: 1.8x
Iteration 67:
- A_psd = eigenvectors @ np.diag(eigenvalues) @ eigenvectors.T
+ # Eliminate intermediate array
+ A_psd = (eigenvectors * eigenvalues) @ eigenvectors.T
Performance: 15.2x
Final (Iteration 95):
def solve(problem):
import numpy as np
A = np.array(problem["matrix"])
w, v = np.linalg.eigh(A)
# One-line vectorized operation
A_psd = (v * np.maximum(w, 0)) @ v.T
return {"projected_matrix": A_psd.tolist()}
Performance: 32.7x speedup
Example 3: DCT Optimization - Convergent Evolution
Original:
def solve(problem):
import numpy as np
from scipy.fftpack import dct
signal = np.array(problem["signal"])
return {"dct": dct(signal, type=1).tolist()}
Multiple Models Converged to Same Solution:
Gemini Flash 2.5:
signal = np.array(problem["signal"], dtype=np.float64)
result = dct(signal, type=1, norm=None, overwrite_x=False)
Qwen3-Coder:
signal = np.asarray(problem["signal"], dtype=np.float64)
return {"dct": dct(signal, type=1).tolist()}
Key Finding: Both discovered dtype=np.float64 optimization independently!
- 6.48x speedup for both
- Shows optimal solution exists and is discoverable
Example 4: SHA256 - Hardware Limitations
Original:
def solve(problem):
import hashlib
data = problem["data"].encode('utf-8')
hash_object = hashlib.sha256(data)
return {"hash": hash_object.hexdigest()}
Best Evolution (multiple models):
def solve(problem):
import hashlib
return {"hash": hashlib.sha256(problem["data"].encode()).hexdigest()}
Performance: Only 1.1x speedup Learning: Hardware-bound operations have limited optimization potential
Model Comparison
For a comprehensive view of all 10 unique models tested, see Panel C in the Executive Dashboard. The complete 29-experiment results are shown in the Performance Rankings chart above.
Task-Specific Performance Heatmap
This heatmap shows speedup factors achieved by different models on specific AlgoTune tasks. Darker red indicates higher speedup. Notable patterns:
- Count connected components shows extreme variation (95x for Flash 2.5 vs 15x for Gemma 3)
- PSD projection achieved consistent high performance across models (32-42x)
- Hardware-bound tasks like SHA256 show minimal improvement regardless of model
Specialization vs Size Analysis
Qwen3-Coder (480B MoE, 35B active) vs Qwen3-235B:
- Despite being "larger" (480B total parameters), Qwen3-Coder has only 35B active
- Coding specialization led to 68% better performance (1.41x vs 0.84x)
- Evidence that training data and objectives matter more than size
Evolution Strategy by Model Capability
| Model Type | Best Strategy | Evidence | |------------|---------------|----------| | Small/Weak (Flash Lite) | Full rewrite | 0.79x with diff vs 1.10x full | | Strong Coding (Flash 2.5, Qwen3-Coder) | Diff-based | 1.64x vs lower with full | | General Purpose | Varies | Model-dependent |
Ensemble Experiments: Why More Models ≠ Better Results
Despite combining our two best performers (Gemini Flash 2.5 at 1.64x and Qwen3-Coder at 1.41x), the ensemble achieved only 1.23x speedup - worse than either model individually.
Visualization Guide:
- Panel A: Shows individual model performance vs ensemble - ensemble underperforms both models
- Panel B: All 30 Tasks Performance Comparison - complete performance profiles for Gemini, Qwen, and Ensemble
- Panel C: Evolution progress comparison - ensemble shows irregular oscillation vs smooth single model progress
- Panel D: Model Agreement by Task - 3x30 heatmap showing pairwise agreement for each task, revealing conflict zones
Key Finding: Conflicting Optimization Strategies
The ensemble failed because models pursued incompatible approaches:
- Count Connected Components: Gemini used BFS, Qwen used Union-Find → oscillation
- DCT Optimization: Different dtype strategies → lost optimizations
- Result: 19% underperformance vs expected 1.5-1.7x
Example: Algorithm Conflict
# Iteration N: Gemini suggests BFS
queue = deque([start]) # BFS approach
# Iteration N+1: Qwen suggests Union-Find
parent = list(range(n)) # Different algorithm!
# Result: Hybrid mess that optimizes neither
Observed Ensemble Failure Modes
- Algorithm conflicts: BFS vs Union-Find approaches in same task
- Optimization conflicts: Memory optimization vs compute optimization
- Style conflicts: Functional vs imperative code patterns
Technical Implementation Details
OpenEvolve Configuration
# Optimal configuration discovered
max_iterations: 200 # More is better
diff_based_evolution: true # For capable models
temperature: 0.4 # For Gemini, 0.6 for others
max_tokens: 16000 # Sweet spot
num_top_programs: 3
num_islands: 4
migration_interval: 20
migration_rate: 0.1
include_artifacts: true # Critical for performance
Island Evolution Dynamics
- 4 islands maintain diversity
- Migration every 20 iterations prevents premature convergence
- Each island can discover different solutions
- Best program tracked globally
Cascade Evaluation Benefits
- Stage 1: Quick syntax/import validation (< 1s)
- Stage 2: Small test cases (< 10s)
- Stage 3: Full benchmark suite (< 60s)
Saved ~70% of evaluation time by failing fast.
Key Observations from Experiments
1. Performance Improvements by Type
- Algorithmic changes (DFS → BFS): Up to 95x speedup observed
- Vectorization optimizations: 32x speedup achieved in matrix operations
- Minor code changes (variable renaming, loop adjustments): Typically < 2x speedup
2. Model Solution Diversity
- Count connected components: Gemini found BFS approach, Qwen found Union-Find
- Matrix operations: Different models used different vectorization strategies
- Multiple valid optimization paths were discovered for most tasks
3. Evolution Strategy Performance
- Diff-based evolution with strong coding models: Up to 1.64x overall speedup
- Full rewrite with weaker models: 1.10x speedup (vs 0.79x with diffs)
- Model capability determined optimal strategy
4. Iteration Impact
- 100 iterations: 1.64x average speedup achieved
- 200 iterations: 2.04x average speedup (24% improvement)
- Performance continued improving through 200 iterations
5. Parameter Effects
- Temperature 0.4: Best individual run (1.291x) but high variance
- Including artifacts: ~17% performance improvement observed
- Token limit: 16k vs 32k showed no significant difference
- Migration rate: 0.1 outperformed 0.2 in experiments
6. Parallelism Impact
- Serial evaluation: 0.396x-0.585x speedup (performance degradation)
- Parallel evaluation: 0.793x-1.10x speedup for same configurations
- Time difference: 13 hours (serial) vs 0.9 hours (parallel)
Conclusions
Key Experimental Findings
- Iteration Count: 200 iterations achieved 2.04x speedup vs 1.64x for 100 iterations (24% improvement)
- Model Specialization: Qwen3-Coder (coding-specialized) outperformed larger general models
- Temperature Settings: Results varied - best individual run at 0.4, but high variance observed
- Evolution Strategy: Diff-based worked better for strong coding models, full rewrite for weaker models
- Parallelism: Serial evaluation degraded performance by 47-50% and increased time 14x
- Ensemble Results: Combined models achieved 1.23x vs 1.64x and 1.41x individually
Observed Patterns
- Models discovered different algorithmic approaches (BFS vs Union-Find for graph problems)
- Hardware-bound tasks (SHA256) showed minimal improvement across all configurations
- Artifacts inclusion improved performance by approximately 17%
- Migration rate of 0.1 performed better than 0.2 in tested configurations