
.jpg&w=2048&q=75)
RUN BIG MODELS | RUN LONG CONTEXT | MAXIMIZE UTILIZATION
dnet is a distributed inference framework for Apple Silicon that can operate with different execution strategies:
- ✅ Pipelined-ring – Run >32B 8-bit models across devices with insufficient total memory
- 🚧 Long context – Make >128K context windows a reality for home clusters
- 🚧 High throughput – Maximize throughput via tensor parallelism
- 🚧 Unified backend – A single optimized backend for Apple Silicon, NVIDIA, and AMD (currently Apple Silicon only, via MLX)
The Problem
Local AI works well for generating a few hundred tokens, but to make it a genuine alternative to cloud-based AI, we need to replicate the full capabilities of cloud providers. Frameworks like vLLM and SGLang are powerful inference engines optimized for production deployments. Yet their design assumptions leave critical gaps for local AI adoption:
- Heterogeneous device support: Both frameworks assume homogeneous GPU clusters. There's no native support for combining different device types (e.g., Apple Silicon Macs alongside NVIDIA GPUs) in distributed inference.
- Accessible cluster creation: These frameworks target datacenter infrastructure with high-end GPUs, not ad-hoc clusters built from consumer hardware with varying capabilities.
- Low-memory optimization: While memory management options exist (quantization, chunked prefill, cpu offloading), the runtime strategies aren't tuned for constrained consumer setups where total cluster memory may barely fit the model.
- Workload assignment: Local clusters are everyday machines—capacity varies, networks are inconsistent, and resources are shared with other apps especially in UMA.
- UMA-aware memory strategies: Apple Silicon's unified memory architecture requires specialized offloading patterns.
EXO is a pioneering initiative that addressed some of these needs, but it has since gone closed-source, is difficult to install, and lacks certain optimizations.
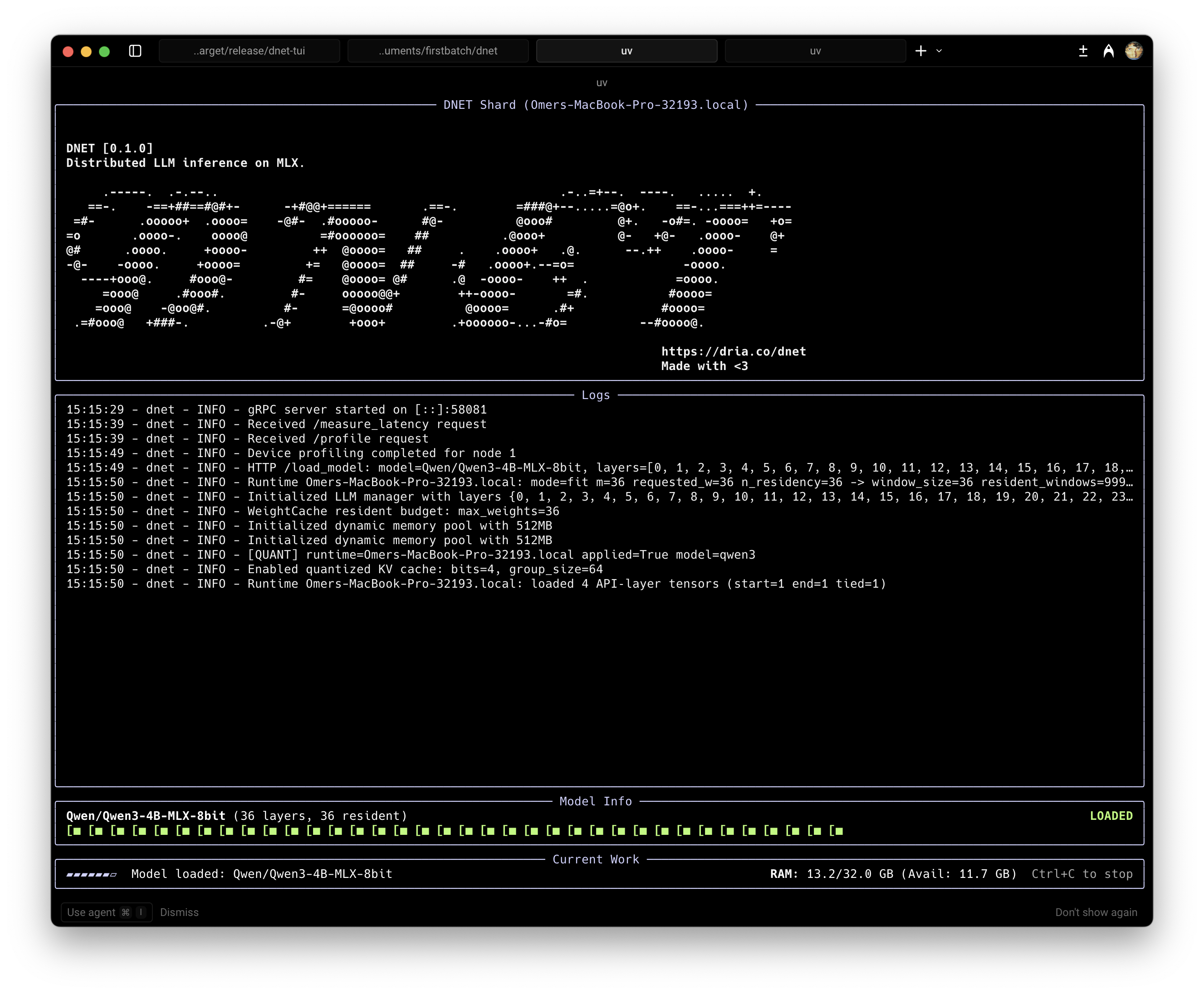
Introducing DNET
dnet is a distributed inference framework built on MLX, specifically designed for ease of use. It is currently in alpha (v0.0.1).
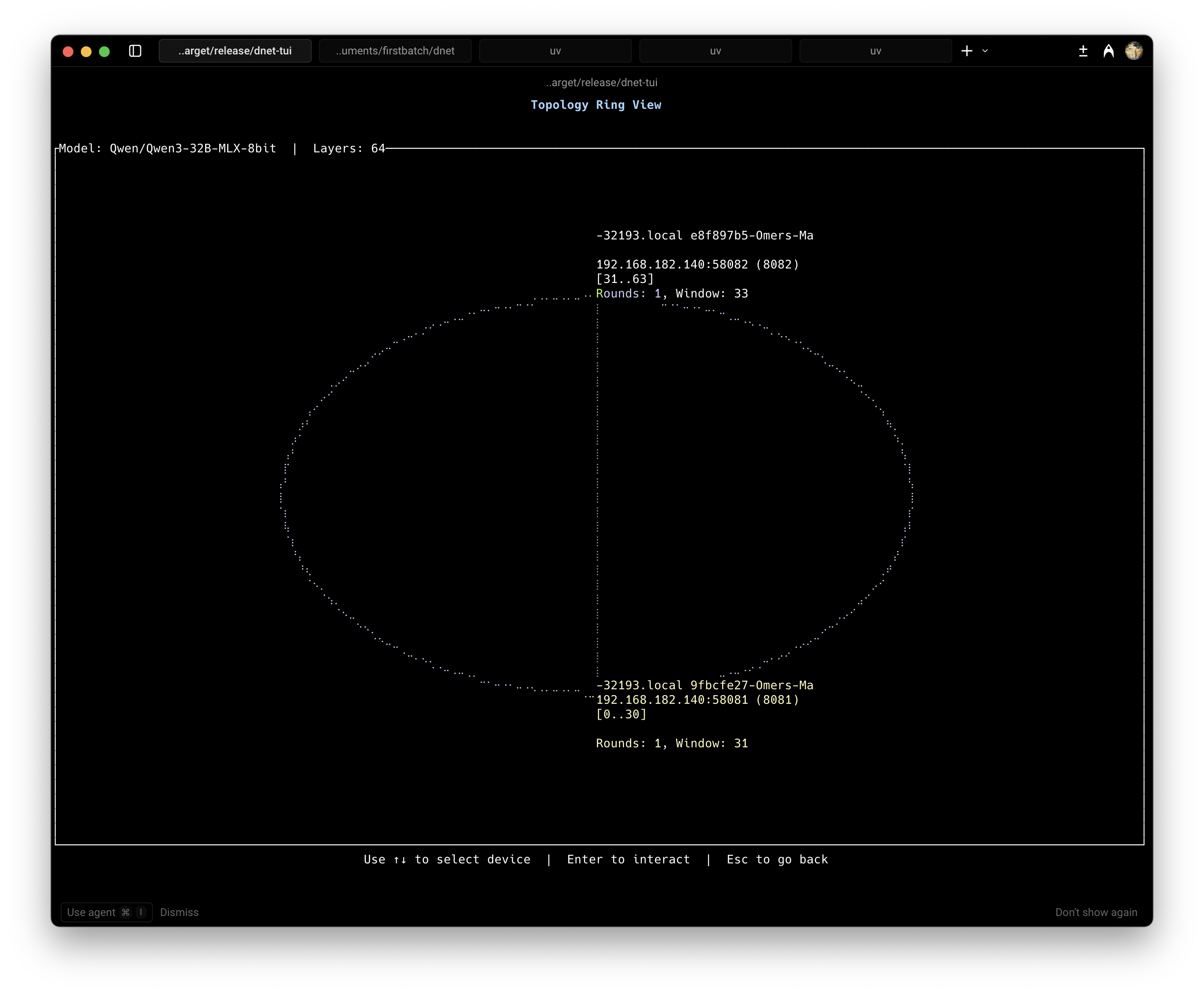
Design Philosophy
dnet structures the inference lifetime around three core components:
Strategy → Profiling → Scheduling
- Strategy defines how dnet distributes and executes model inference across devices. This encompasses the communication pattern, layer assignment logic, and execution flow.
- Profiling devices for FLOPs, memory, and inter-device latency; models are profiled for their compute and memory requirements.
- Solver: Layer and tensor assignment is handled by a solver built on
distilp, which performs heterogeneity-aware assignments by accounting for:- Inter-device latency
- KV cache size and quantization
- Model architecture
- Per-device FLOPs and memory
- Disk Speed
Unlike simple partitioning schemes, this enables optimal distribution across mixed-capability devices, assigning heavier layers to faster devices while respecting memory constraints.
Alpha Release
We're releasing dnet in alpha, along with two libraries we built to support it: dnet-p2p handles async device discovery and Thunderbolt detection; distilp solves for optimal layer assignments across heterogeneous devices for different strategies.
In alpha, dnet builds on prima.cpp's pipelined-ring parallelism, extending it via distilp with smarter scheduling. This enables running models across multiple devices beyond total available memory while minimizing latency through compute and I/O overlap.
Going Further: distilp.halda_solve()
DNET’s , distilp, extends PRIMA.CPP’s HALDA with two key enhancements:
Intra-device offloading. PRIMA.CPP limits each device's window to what fits in memory; if a device holds 8 layers, it gets 8 layers. DNET’s distilp relaxes this constraint. If a device's optimal window is 9 layers, even if read time from disk is considered, but it can only hold 8, distilp allows it—the extra layer streams from disk mid-round, overlapped with ongoing computation. This lets devices punch above their memory weight.
Cycle-time formulation. Rather than summing latencies naively, distilp models the ring as a coordinated system with a shared cycle time. Each device has busy time (compute + intra-device offloading) and fetch time (prefetching next round's layers). A device only stalls when its fetch exceeds the slack created by the rest of the ring. The cycle time is determined by whichever device takes longest—meaning faster devices naturally absorb delays from slower ones.
UMA-aware scheduling. Apple Silicon's unified memory means CPU and GPU compete for the same memory pool. Standard mmap-based loading can overcommit and trigger swapping under pressure. distilp addresses this with three changes: memory pressure buffers that reflect UMA's shared allocation, Apple-specific loaders for predictable memory behavior, and reorganizing weights with repacking so that layers stream efficiently during ring execution rather than requiring random access patterns.
Extensibility
dnet is designed around a plugin architecture. Each execution strategy is composed of three adapters
| Component | API Side | Shard Side |
|---|---|---|
| Solver | How to distribute layers across devices | - |
| API Adapter | How the API communicates with the first shard | - |
| Topology Adapter | - | How shards communicate with each other |
For pipelined-ring, this looks like:
RingStrategy
├── RingTopologySolver -> Runs distilp, optimizes device ordering, computes layer assignments
├── RingApiAdapter -> Streams tokens to first shard, awaits results
└── RingAdapter (shard)-> Ingress/egress workers, forwards activations around the ring
To implement a new strategy you extend both dnet and distilp:
In distilp: Implement a solver for your strategy's distribution problem. Different strategies have different constraints; the solver can be greedy, use ILP, or any method of your choice
In dnet: Extend the base adapters with your communication pattern:
class TensorParallelStrategy(Strategy):
solver = TensorParallelSolver() *# Calls distilp solver*
adapter = TensorParallelApiAdapter() *# All-to-all instead of ring*
...
The runtime, model loading, KV cache management, and OpenAI API remain unchanged—only the distribution logic and communication patterns differ.
What's Next
dnet is alpha software; pipelined-ring works, but there's more to build:
- Enabling longer context locally.
- Higher throughput with faster communication backends and RDMA.
- Unified backend to bring NVIDIA and AMD into the same cluster as Apple Silicon and optimize both per device and topology.
We're building dnet because we believe local AI shouldn't require datacenter assumptions. We also believe local AI will be a crucial backbone for agentic work, both personal and global. The only way to achieve this is to maximize utilization of local clusters while keeping everything easy to use.
Try it:
We'd love feedback, bug reports, and contributions.
Acknowledgements
dnet is built on top of MLX and inspired by pioneering work in distributed inference:
PRIMA.CPP: Prima.cpp: Fast 30-70B LLM Inference on Heterogeneous and Low-Resource Home Clusters